Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
Anurag Chowdhury - About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Detecting human speech and identifying its source, i.e., the speaker, from speech audio is an active area of research in Machine learning and Biometrics community. As with other types of digital signals such as images and video, an audio signal can undergo degradations during its generation, propagation, and recording. Identifying the speaker from such degraded speech data is a challenging task and an open research problem. In this research project, we work on developing deep learning-based algorithms for speaker recognition from degraded audio signals. We use speech features like Mel-Frequency Cepstral Coefficients (MFCC) and Linear Predictive Coding (LPC) for representing the audio signals. We design one-dimensional convolutional neural networks (1D-CNN) which learn speaker dependent features from the MFCC and LPC based speech representations for performing speaker recognition. We have also develop 1D-CNN based audio filterbank for extracting robust speaker-dependent speech features directly from raw speech audio.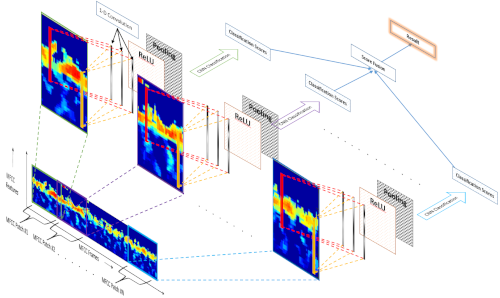
Speaker recognition is the task of determining a person’s identity from their voice. The human voice, as a biometric modality, is a combination of physiological and behavioral characteristics. The voice production system’s physical traits determine the human voice’s physiological characteristics, while the prosodic (pitch, timbre) and high-level (lexicon) traits impart the human voice’s behavioral characteristics. In this work, we develop deep learning-based models for extracting speaker-dependent behavioral speech characteristics. These behavioral characteristics are then combined with speaker-dependent behavioral speech characteristics to improve speaker recognition performance in degraded audio signals. We further design a deep learning-based speech synthesis framework that uses these behavioral speech characteristics for generating highly realistic synthetic speech samples. 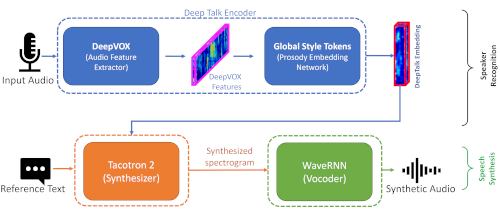
Indoor video surveillance systems often use the face modality to establish the identity of a person of interest. However, the face image may not offer sufficient discriminatory information in many scenarios due to substantial variations in pose, illumination, expression, resolution and distance between the subject and the camera. In such cases, the inclusion of an additional biometric modality can benefit the recognition process. In this regard, we consider the fusion of voice and face modalities for enhancing the recognition accuracy. We use current state-of-art deep learning based methods to perform face and speaker recognition dataset for establishing baseline performance of individual modalities. We explore multiple fusion schemes, at data, feature, score, and decision levels, to combine face and speaker modalities to perform effective biometric recognition in video data.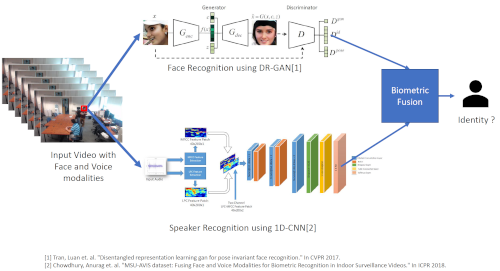
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1). http://academicpages.github.io/files/paper1.pdf
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2). http://academicpages.github.io/files/paper2.pdf
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3). http://academicpages.github.io/files/paper3.pdf
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.