Speaker Recognition From Degraded Audio Samples
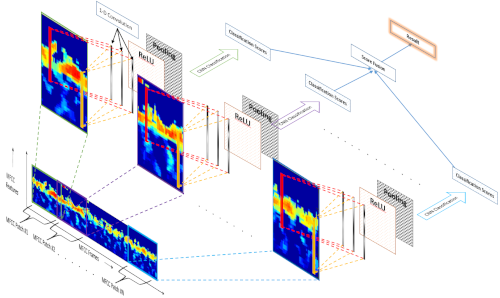
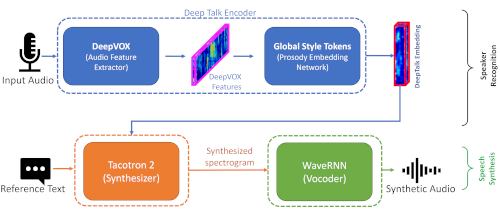
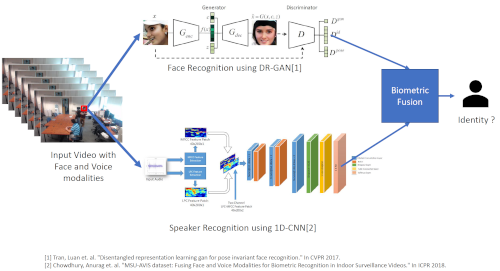
Detecting human speech and identifying its source, i.e., the speaker, from speech audio is an active area of research in Machine learning and Biometrics community. As with other types of digital signals such as images and video, an audio signal can undergo degradations during its generation, propagation, and recording. Identifying the speaker from such degraded speech data is a challenging task and an open research problem. In this research project, we work on developing deep learning-based algorithms for speaker recognition from degraded audio signals. We use speech features like Mel-Frequency Cepstral Coefficients (MFCC) and Linear Predictive Coding (LPC) for representing the audio signals. We design one-dimensional convolutional neural networks (1D-CNN) which learn speaker dependent features from the MFCC and LPC based speech representations for performing speaker recognition. We have also develop 1D-CNN based audio filterbank for extracting robust speaker-dependent speech features directly from raw speech audio.